1. 개요
mediapipe의 hand 기능을 사용하여 웹캠을 통해 gesture를 판단하는 모델을 만들 것이다.
2. mediapipe hand
우리가 사용할 것은 Mediapipe의 hand 기능이다.

사진과 같이 손의 랜드마크를 21개로 구분하여 감지한다.
각각의 랜드마크는 x,y,z의 좌표로 구성되어 있다.

자세한 것은 아래에서 코드를 통해 보자.
3. gesture 모델
전체 코드는 다음과 같다.
import cv2
import mediapipe as mp
import numpy as np
max_num_hands = 1 # 손 인식 개수
gesture = {
0:'0',
1:'1',
2:'2',
3:'3',
4:'4',
5:'5',
6:"good",
7:"ok",
8:"peace"
}
# MediaPipe hands model
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
# 손가락 detection 모듈을 초기화
hands = mp_hands.Hands(
max_num_hands=max_num_hands,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
# 제스처 인식 모델
file = np.genfromtxt('hand_data/merged_hand_angles.csv', delimiter=',')
angle = file[:,:-1].astype(np.float32) # 각도
label = file[:, -1].astype(np.float32) # 라벨
knn = cv2.ml.KNearest_create() # knn(k-최근접 알고리즘)
knn.train(angle, cv2.ml.ROW_SAMPLE, label) # 학습
cap = cv2.VideoCapture(0)
while cap.isOpened(): # 웹캠에서 한 프레임씩 이미지를 읽어옴
ret, img = cap.read()
if not ret:
continue
img = cv2.flip(img, 1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = hands.process(img)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 각도를 인식하고 제스처를 인식하는 부분
if result.multi_hand_landmarks is not None:
for res in result.multi_hand_landmarks:
joint = np.zeros((21, 3))
for j, lm in enumerate(res.landmark):
joint[j] = [lm.x, lm.y, lm.z] # 각 joint마다 x,y,z 좌표 저장
v1 = joint[[0,1,2,3,0,5,6,7,0,9,10,11,0,13,14,15,0,17,18,19],:]
v2 = joint[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],:]
v = v2 - v1
# 뼈의 길이 벡터
v = v / np.linalg.norm(v, axis=1)[:, np.newaxis] # 벡터 정규화(크기 1 벡터) = v / 벡터의 크기
# 손의 움직임을 구성하는 주요 긱도 15개의 각도를 계산
angle = np.arccos(np.einsum('nt,nt->n',
v[[0,1,2,4,5,6,8,9,10,12,13,14,16,17,18],:],
v[[1,2,3,5,6,7,9,10,11,13,14,15,17,18,19],:]))
angle = np.degrees(angle) # radian 각도를 degree 각도로 변환
data = np.array([angle], dtype=np.float32)
ret, results, neighbours, dist = knn.findNearest(data, 3) # k가 3일 때 값을 구한다
idx = int(results[0][0])
if idx in gesture.keys():
cv2.putText(img, text=gesture[idx].upper(), org=(int(res.landmark[0].x * img.shape[1]), int(res.landmark[0].y * img.shape[0] + 20)), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(255, 255, 255), thickness=2)
mp_drawing.draw_landmarks(img, res, mp_hands.HAND_CONNECTIONS) # 손에 랜드마크를 그려줌
cv2.imshow('Game', img)
if cv2.waitKey(1) == ord('q'):
break
코드에서 중요한 부분을 자세히 설명하자면
1) gesture 라벨
모델의 라벨이다.
result[0][0]이 key에 해당하는 부분이고, 이에 따라 화면에 라벨값이 표출된다.
gesture = {
0:'0',
1:'1',
2:'2',
3:'3',
4:'4',
5:'5',
6:"good",
7:"ok",
8:"peace"
}
2) 각도 구하기
손의 모델을 학습하기 위해서 뼈와 뼈사이의 각도를 학습시킨다.
v = v2 - v1을 보면
v벡터는 아래 사진의 뼈의 길이(파란 선) 벡터이다.
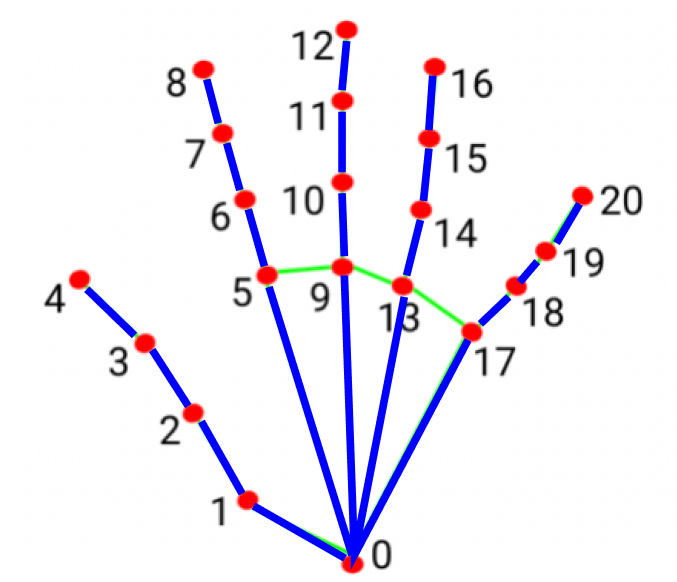
v벡터를 먼저 정규화한 후 손의 움직임을 구성하는 주요 각도(빨간 선) 15개의 각도를 계산한다.
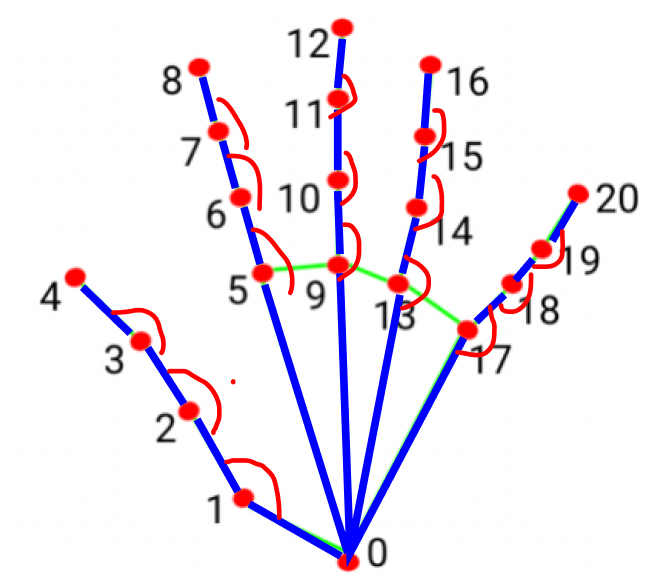
이 각도를 바탕으로 학습을 시켜 모델을 라벨링한다.
v1 = joint[[0,1,2,3,0,5,6,7,0,9,10,11,0,13,14,15,0,17,18,19],:]
v2 = joint[[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],:]
v = v2 - v1
# 뼈의 길이 벡터
v = v / np.linalg.norm(v, axis=1)[:, np.newaxis] # 벡터 정규화(크기 1 벡터) = v / 벡터의 크기
# 손의 움직임을 구성하는 주요 뼈 15개의 각도를 계산
angle = np.arccos(np.einsum('nt,nt->n',
v[[0,1,2,4,5,6,8,9,10,12,13,14,16,17,18],:],
v[[1,2,3,5,6,7,9,10,11,13,14,15,17,18,19],:]))
angle = np.degrees(angle) # radian 각도를 degree 각도로 변환4. 결과
1. good

2. ok

training data set - 812개
test data set - 206개
정확도 : 88.41%
0과 good이 엄지 손가락을 제외하고 각도가 비슷하기 때문에 다른 라벨에 비해 구분이 잘 안되는 것을 확인할 수 있다.
조금 더 많은 data set을 넣으면 더 높은 정확도를 도출할 것이다.

5. data file
8개의 라벨에 대한 812개의 data set이다.
각 row에는 15개의 각도와 label로 이루어져있다.
'Sign Tracker' 카테고리의 다른 글
| KNN 알고리즘 (0) | 2024.10.06 |
|---|